LASSO regularisation
Last updated on 2025-11-04 | Edit this page
Overview
Questions
- How do we avoid overfitting in multiple linear regression?
Objectives
- Explain the rationale behind regularisation in linear regresssions
- Demonstrate how to perform a LASSO-regularisation
- Demonstrate how to use cross-validation to optimise the hyperparamter.
Least Absolute Shrinkage and Selection Operator.
One of the risks when we build a linear model based on several predictive variables, is that we add too many variables to the model. We should always try to build a parsimonius model, one that only include the variables that actually contribute to the predictive value of the model.
Adding too many variables, can lead to overfitting, and in turn bad predictions on new data.
But which variables should we include?
Guessing is often a viable route to take, but we run the risk of letting our own biases influence the model.
Rather than guessing, techniques for letting the computer make the choices for us, exist.
One of these is called “LASSO” - Least Absolute Shrinkage and Selection Operator. Probably a bacronym.
When we normally build a linear model, we ask the algorithm to identify the coefficients in the expression:
\[\hat{y}= \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3x_3 +... + \beta_nx_n\]
We explicitly want a model that minimises the difference, residual, between the “true” values of y that we know, and the prediction the model makes, \(\hat{y}\).
The algorithm that does all the work for us, do that by minimising the so called loss-function, typically the sum of the square of the residuals:
\[RSS = \sum(y_i - \hat{y_i})^2\]
In the LASSO algorithm, we instead minimise this loss-function:
\[\sum_{i=1}^{n}(y_i - \sum_{j} x_{ij}\beta_j)^2 + \lambda\sum_{j=1}^p |\beta_j|\]
Or, a bit shorter:
\[RSS + \lambda\sum_{j=1}^p |\beta_j|\]
The additional term, \(\lambda\sum_{j=1}^p |\beta_j|\) sum the absolute values of all the coefficients (except for the intercept), and multiplies it with a parameter \(\lambda\).
The additional term regulates, or regularises the solution, and prevent the model from being too flexible. We therefor call this technique LASSO-regularisation. Others exist, and LASSO is often also called L1-regularisation.
Mathematically this has the consequence that we might get the minimum of the loss function by setting some coefficients \(\beta\) to zero. In that way, the LASSO algorithm can eliminate coefficients, and thereby variables in the model, that do not contribute enough to the overall model.
\(\lambda\) controls how severe we punish the model for having too many or to large coefficients. Therefore we still have to chose the value of \(\lambda\) when we build the model using LASSO regularisation.
Let us look at an example.
First of all we need a package to do the calculations for us.
glmnet is one such package:
R
library(tidyverse)
library(glmnet)
OUTPUT
Loading required package: MatrixOUTPUT
Attaching package: 'Matrix'OUTPUT
The following objects are masked from 'package:tidyr':
expand, pack, unpackOUTPUT
Loaded glmnet 4.1-10We are going to build a model predicting the fuel efficiency,
mpg based on other parameters (cyl, disp, hp, drat, wt,
qsec), in the mtcars dataset
First - this is the result in a ordinary linear model (OLS):
R
lm_model <- lm(mpg ~ cyl + disp + hp + drat + wt + qsec, data = mtcars)
coef(lm_model)
OUTPUT
(Intercept) cyl disp hp drat wt
26.30735899 -0.81856023 0.01320490 -0.01792993 1.32040573 -4.19083238
qsec
0.40146117 Some datamanipulation is needed in order to remove categorical
variables. The implementation of LASSO in glmnet also
require that the response variable is provided in a vector, and the
predictor variables in a matrix:
R
y <- mtcars$mpg
x <- as.matrix(mtcars[,c(2:7)])
Now we are ready to run the regression with LASSO regularisation. The
function is also called glmnet. As mentioned other
regularisation techniques exist, and we chose LASSO by setting the
argument alpha to 1. We also have to chose \(\lambda\) ourself. We make a first attempt
with 1.5.
R
L1_model <- glmnet(x,y,alpha = 1, lambda = 1.5)
coef(L1_model)
OUTPUT
7 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 33.593471359
cyl -0.835573047
disp .
hp -0.006175254
drat .
wt -2.308463917
qsec . | coef | LASSO | OLS |
|---|---|---|
| (Intercept) | 33.593471359 | 26.30735899 |
| cyl | -0.835573047 | -0.81856023 |
| disp | 0.000000000 | 0.01320490 |
| hp | -0.006175254 | -0.01792993 |
| drat | 0.000000000 | 1.32040573 |
| wt | -2.308463917 | -4.19083238 |
| qsec | 0.000000000 | 0.40146117 |
Note that the coefficients for disp, drat
and qsec are eliminated, or set to zero in the
LASSO-regression.
But we still made a choice by setting \(\lambda\) to 1.5. What is the optimal \(\lambda\)?
The optimal \(\lambda\) is the \(\lambda\) that leads to a model that best predict the response variable.
Challenge
Suggest one way to find the optimal \(\lambda\)
We could do that by splitting the data in two parts, build different models on one part with different \(\lambda\) s and use them to predict the results for the other part of the data. The model that best predicts the data is the best, and we know which \(\lambda\) was the best.
Our dataset is not very large. If we pull out a fifth of the dataset for evaluation purposes, we only have 25 observations left.
And what if the random split of our data by chance happen to be bad? We run the risk of splitting it in a way where we do not have a representative sample for training. Would we get the same result if we split it in a different way?
How do we handle this?
We handle this problem with the randomness of sampling, and the limited size of our data, by splitting (sampling) the data randomly a number of times (often 10). For each random split we test different values of \(\lambda\), and then calculate the average of how well a given value of \(\lambda\) perform, for the 10 different splits. We can then chose the best \(\lambda\), and build a final model using that.
glmnet provides a function for handling all that. We can
chose which \(\lambda\) s the function
should test, we can chose another number of random selections (folds)
than the default 10 and a lot of other details. We go with the defaults
here:
R
set.seed(47) # The folds are selected at random - this line of code makes those reproducable
model <- cv.glmnet(x, y, alpha = 1)
Our model now contains results for many different \(\lambda\)s
If we plot it, we get the mean-squared-error on the y-axis. That is the value we want to minimise, and \(\log{\lambda}\) on the x-axis:
R
plot(model)
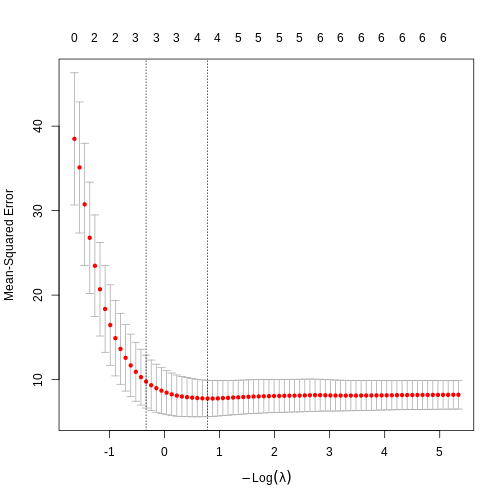
The numbers above the plot indicates the number of variables left in the model for at given \(\lambda\). To the far left, we do not eliminate any variables. To the far right, only two are left.
We could look at the plot and determine the best value of \(\lambda\). The first is
lambda.min which is the \(\lambda\) that, on average, give the lowest
error, and lambda.1se which is the largest \(\lambda\) that give an error within one
standarderror of the minimum.
Which should we chose? lambda.min give us the lowest error when we want to predict values, but have more variables left in the model. lambda.1se accepts a larger (but not large) error , but returns a simpler model.
Lets go with lambda.min
R
best_l <- model$lambda.min
best_l
OUTPUT
[1] 0.458192Now we know which lambda to use, and we can fit the overall model:
R
best_model <- glmnet(x,y,alpha = 1, lambda = best_l)
coef(best_model)
OUTPUT
7 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 36.29975118
cyl -0.87369436
disp .
hp -0.01497565
drat 0.16884990
wt -2.86383756
qsec . - It is important to avoid overfitting in multiple linear regression.
- LASSO can remove unnessecary variables in linear models.
- Cross validation can optimise the LASSO regularisation.