library(tidyverse)Stacked barcharts
Of gendered time use in Denmark
R
ggplot
How to make a stacked barchart
As usual, we read in tidyverse:
We also need some data. OECD have data on how people spend their time in different countries..
We grab their “Developer API”, get the url to a data query, and add “&format=csvfilewithlabels” to get data in a format that is not too difficult to handle.
url <- "https://sdmx.oecd.org/public/rest/data/OECD.WISE.INE,DSD_TIME_USE@DF_TIME_USE,1.0/all?dimensionAtObservation=AllDimensions&format=csvfilewithlabels"We can read in that directly:
df <- read_csv(url)Rows: 525 Columns: 20
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (16): STRUCTURE, STRUCTURE_ID, STRUCTURE_NAME, ACTION, REF_AREA, Referen...
dbl (3): OBS_VALUE, DECIMALS, UNIT_MULT
lgl (1): Observation value
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.The specification of columns reveals that there are a lot that we do not really need. So we select a more modest selection. That leaves us with time used, on what, sex and a total. The total is redundant - we get rid of that as well.
df <- df %>%
select(Country = `Reference area`, Measure, Sex = SEX, time = OBS_VALUE) %>%
filter(Sex != "_T")There are a lot of data, so we are only going to consider Denmark.
We filter to only leave Denmark and change M and F to ♂ and ♀. :
df <- df %>%
filter(Country == "Denmark") %>%
mutate(Sex = case_match(Sex,
"M" ~ "♂",
"F" ~ "♀️",
.default = Sex))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `Sex = case_match(Sex, "M" ~ "♂", "F" ~ "♀️", .default = Sex)`.
Caused by warning:
! `case_match()` was deprecated in dplyr 1.2.0.
ℹ Please use `recode_values()` instead.And now we are ready to make the stacked barchart
Og så kan vi lave søjlediagrammet.
Vi styrer tingene to steder i koden. I aes() fortæller vi hvad der er på x- og y-akserne. Farvelægningen styres samme sted (husk fill i stedet for color), og med den får vi samtidig grupperet vores data - og det bruges i geom_col. Her specificerer vi nemlig at det skal stakkes. Vi kunne også have skrevet “dodge”, men målet var et stakket søjlediagram, så…
Hvorfor geom_col i stedet for geom_bar? geom_bar foretager som default en statistisk transformation på data, hvor den tæller antallet af observationer. Nu var det ikke antallet af observationer af tidsforbrug vi ville have (de er nemlig ens), men tallene selv. geom_col laver ingen transformation. Vi kunne også have givet geom_bar argumentet stat = "identity", det havde for de fleste praktiske formål givet samme resultat.
Og så justerer vi på labels i plottet, fjerner clutter fra default temaet, og justerer på farverne:
df %>%
mutate(Measure = factor(Measure,
levels = c("Andet", "Personlig Pleje",
"Fritid", "Ulønnet arbejde", "Lønarbejde eller studier"))) |>
ggplot(aes(x = Sex, y = time, fill = Measure)) +
geom_col(position = "stack") +
labs(
title = "Stakkede søjlediagrammer for de to køns tidsforbrug",
x = "",
y = "Tid (minutter)",
fill = "Aktivitet"
) +
theme_minimal() +
scale_fill_brewer(palette = "Set2")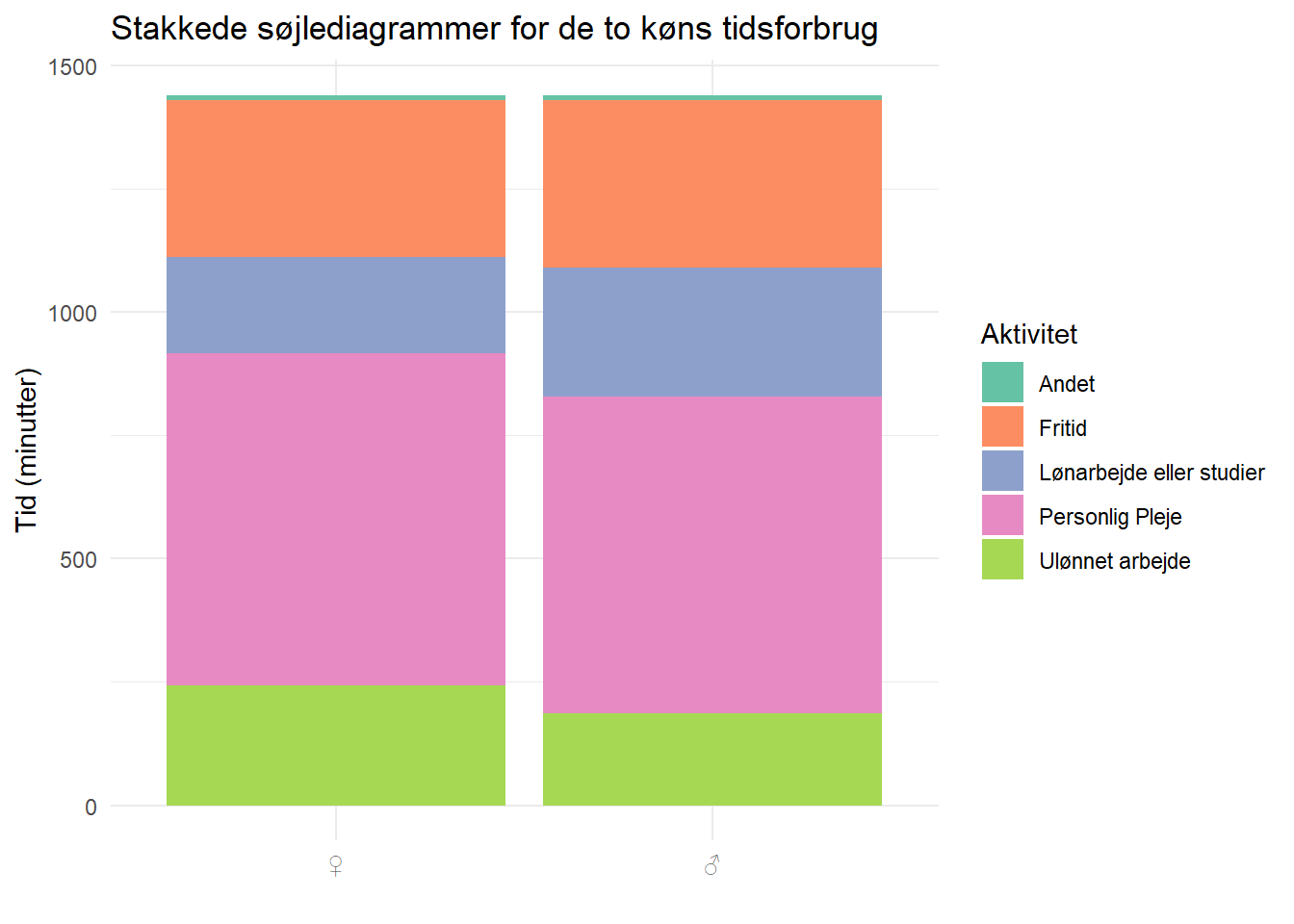
Bum. De to søjler er her, helt naturligt, lige høje, for der er ikke forskel på hvad de to køn har af tid i løbet af en dag.
Det er dog lidt vanskeligt at sammenligne. Det er en af udfordringerne med stakkede søjler.
I stedet kan vi dele det lidt op. Vi vælger position = "dodge" for at få søjlerne ved siden af hinanden, ændrer på titlen, og tilføjer facet_wrap(~Measure) for at få et plot for hver type aktivitet der bruges tid på:
df %>%
ggplot(aes(x = Sex, y = time, fill = Measure)) +
geom_col(position = "dodge") +
labs(
title = "Søjlediagrammer for de to køns tidsforbrug",
x = "",
y = "Tid (minutter)",
fill = "Aktivitet"
) +
theme_minimal() +
scale_fill_brewer(palette = "Set2") +
facet_wrap(~Measure)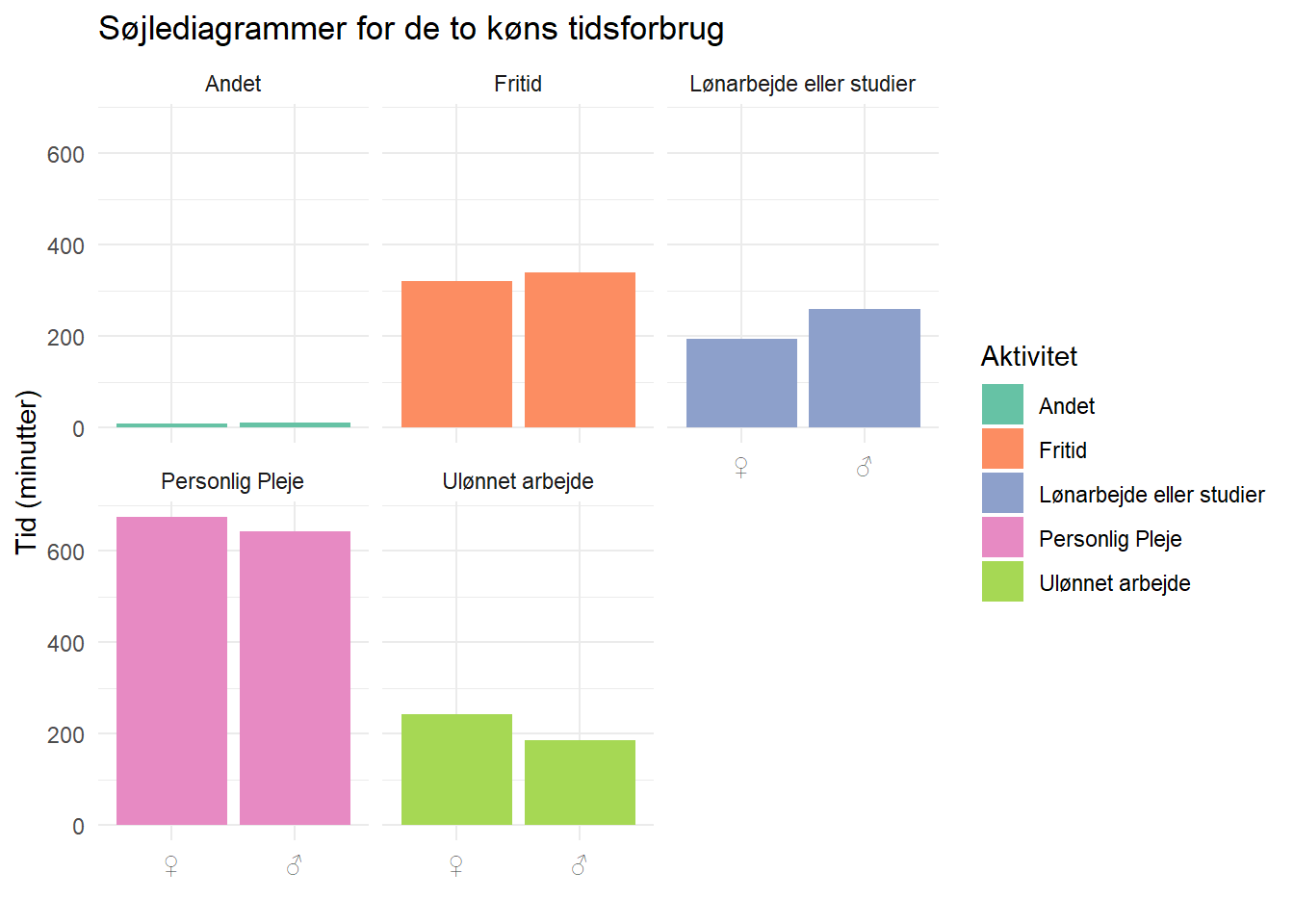
Bum-bum.
Konklusioner? Den eneste jeg tør drage er, at sammenligninger i stakkede søjlediagrammer kan være vanskelige.